Learning from Data to Predict¶
Key themes¶
The prediction task
Supervised learning
Machine learning tasks — e.g., regression (continuous) and classification (binary)
Building and evaluation of simple prediction models
The problem of model overfitting and strategies to avoid it:
Splitting the data into training set and testing set
Cross-validation
Introduction to supervised machine learning algorithms, including k-Nearest Neighbors and Logistic Regression
Learning resources¶
Predictability of life trajectories by Matthew Salganik
Introduction to Machine Learning Methods by Susan Athey
Machine Learning with Scikit Learn by Jake VanderPlas
M Molina & F Garip. 2019. Machine learning for sociology. Annual Review of Sociology. Link to an open-access version of the article available at the Open Science Framework.
Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter, Julia Lane. 2021. Chapter 7: Machine Learning. In Big Data and Social Science (2nd edition).
Aurélien Géron. 2019. Chapter 2: End-to-end Machine Learning project. In Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (2nd Edition). O’Reilly.
The Prediction task¶
Prediction is a data science task among other data science tasks, including description and causal inference. Prediction is the use of data to map some input (X) to an output (Y). The prediction task is called classification when the output variable is categorical (or discrete), and regression when it is continuous. Our focus in this session will be on classification.
Prediction tasks in social sciences¶
There are many prediction problems in social sciences (summarised in Kleinberg et al. 2015) that can benefit from (supervised) machine learning, for example:
In child protection, predicting when kids are in danger;
In the criminal justice system, predicting whether to detain or release arrestees as they await adjudication of their case (e.g., Kleinberg et al. 2015);
In population health, predicting suicides;
In education, predicting which teacher will have the greatest value add (e.g., Rockoff et al., 2011);
In higher education, predicting earlier university dropouts;
In labor market policy, predicting unemployment spell length to help workers decide on savings rates and job search strategies;
In social policy, predicting highest risk youth for targeting interventions (e.g., Chandler et al., 2011);
In sociology, predicting life outcomes (Salganik et al. 2020).
Predictions gone wrong¶
Prediction and machine learning models went wrong in a few occasions in different domains, including public health, education, the criminal justice system, and healthcare:
David Lazer et all. The Parable of Google Flu: Traps in Big Data Analysis. Science.
What went wrong with the A-level algorithm? Financial Times.
Blame the politicians, not the technology, for A-level fiasco.. Financial Times.
Machine Bias. ProPublica.
Ziad Obermeyer at all. Dissecting racial bias in an algorithm used to manage the health of populations. Science.
Regardless of whether you use or not machine learning in your research, knowledge about prediction and machine learning techniques can help you evaluate how those techniques are used across domains and possibly identify ethical challenges and potential biases in those applications. Importantly, such data ethics challenges are found to reside not only in the machine learning algorithms themselves but in the entire data science ‘pipeline’ or ecosystem.
Supervised learning¶
Learn a model from labeled training data or outcome variable that would enable us to make predictions about unseen or future data. The learning is called supervised because the labels (e.g., email Spam or Ham where ‘Ham’ is e-mail that is not Spam) of the outcome variable (Y) that guide the learning process are already known.
Research problem: vaccine hesitancy¶
We will aim to predict people who are unlikely to take a coronavirus vaccine (Y) from socio-demographic and health input features (X). An unbiased prediction of individuals who are unlikely to vaccinate can inform targeted public health interventions, including information campaigns disseminating evidence-based information about Covid-19 vaccines.
Data: Understanding Society COVID-19¶
We will use data from The Understanding Society: Covid-19 Study. The survey asks participants across the UK about their experiences during the COVID-19 outbreak. We use the Wave 6 (November 2020) web-collected survey data. More information about the survey data and questionnaire is available in the study documentation on the UK Data Service website.
The data are safeguarded and is available to users registered with the UK Data Service.
Once access to the data is obtained, the data needs to be stored securely in your Google Drive and loaded in your private Colab notebook. The data is provided in various file formats, we use the .tab file format (tab files store data values separated by tabs) which can be easily loaded using pandas. The web collected data of the survey from Wave 6 (November 2020) is stored in the file cf_indresp_w.tab.
Note
The workflow in this session assumes that learners, first, have registered with the UK Data Service and obtained access to the Understanding Society: Covid-19 Study (Wave 6, November 2020, Web-collected data) and, second, have safely and securely stored the data in their Google Drive as a tab-separated values (TAB) file named cf_indresp_w.tab. If you have not registered with the UK Data Service and have not obtained access to the data, you can still read the textbook chapter and follow the analytical steps but would not be able to work interactively with the notebook.
Accessing data from your Google Drive¶
After you obtain access to the Understanding Society: Covid-19 Study, 2020, you can upload the Wave 6 (November 2020) data set into your Google Drive. Then you will need to connect your Google Drive to your Google Colab using the code below:
# Import the Drive helper
from google.colab import drive
# This will prompt for authorization.
# Enter your authorisation code and rerun the cell.
drive.mount("/content/drive")
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-1-71de872a6421> in <cell line: 2>()
1 # Import the Drive helper
----> 2 from google.colab import drive
3
4 # This will prompt for authorization.
5 # Enter your authorisation code and rerun the cell.
ModuleNotFoundError: No module named 'google.colab'
Note
The above code will execute in Colab but will give an error (e.g., ModuleNotFoundError: No module named 'google') when the notebook is run outside Colab.
Loading the Understanding Society Covid-19 Study (Wave 6, November 2020, Web collected)¶
import pandas as pd
import numpy as np
# Load the Understadning Society COVID-19 Study web collected data, Wave 6
# Set the delimeter parameter sep to "\t" which indicates tabs
USocietyCovid = pd.read_csv(
"/content/drive/My Drive/cf_indresp_w.tab",
sep="\t",
)
# Display all columns in the Understanding Society: COVID-19 Study
pd.options.display.max_columns = None
USocietyCovid.head(0) # display headings only as the data is safeguarded
| pidp | psu | strata | birthy | racel_dv | bornuk_dv | i_hidp | j_hidp | k_hidp | i_ioutcome | j_ioutcome | k_ioutcome | cf_welsh | cf_dobchk | cf_age | cf_sex_cv | cf_addrchk | cf_couplewsh | cf_hhnum | cf_personsexa | cf_personsexb | cf_personsexc | cf_personsexd | cf_personsexe | cf_personsexf | cf_personsexg | cf_personsexh | cf_personsexi | cf_personsexj | cf_personsexk | cf_personagea | cf_personageb | cf_personagec | cf_personaged | cf_personagee | cf_personagef | cf_personageg | cf_personageh | cf_personagei | cf_personagej | cf_personagek | cf_relationa | cf_relationb | cf_relationc | cf_relationd | cf_relatione | cf_relationf | cf_relationg | cf_relationh | cf_relationi | cf_relationj | cf_relationk | cf_couple | cf_hhcompa | cf_hhcompb | cf_hhcompc | cf_hhcompd | cf_hhcompe | cf_parent0plus | cf_parent5plus | cf_parent015 | cf_parent1619 | cf_parent511 | cf_parent1217 | cf_parent418 | cf_scsf1 | cf_ff_hadsymp | cf_clinvuln_dv | cf_hadsymp | cf_hassymp | cf_symptoms1 | cf_symptoms2 | cf_symptoms23 | cf_symptoms24 | cf_symptoms25 | cf_symptoms3 | cf_symptoms4 | cf_symptoms5 | cf_symptoms6 | cf_symptoms7 | cf_symptoms8 | cf_symptoms9 | cf_symptoms10 | cf_symptoms12 | cf_symptoms13 | cf_symptoms14 | cf_symptoms15 | cf_symptoms16 | cf_symptoms17 | cf_symptoms18 | cf_symptoms19 | cf_symptoms20 | cf_symptoms21 | cf_symptoms22 | cf_symptoms11 | cf_cv19treat | cf_cv19trwhat1 | cf_cv19trwhat2 | cf_cv19trwhat3 | cf_cv19trwhat4 | cf_cv19trwhat5 | cf_cv19trwhat6 | cf_cv19trwhat7 | cf_cv19trwhat8 | cf_cv19trwhat9 | cf_cv19trwhat10 | cf_cv19trwhat11 | cf_longcovid | cf_lgcvsymp1 | cf_lgcvsymp23 | cf_lgcvsymp24 | cf_lgcvsymp25 | cf_lgcvsymp3 | cf_lgcvsymp4 | cf_lgcvsymp5 | cf_lgcvsymp6 | cf_lgcvsymp7 | cf_lgcvsymp8 | cf_lgcvsymp9 | cf_lgcvsymp10 | cf_lgcvsymp12 | cf_lgcvsymp13 | cf_lgcvsymp14 | cf_lgcvsymp15 | cf_lgcvsymp16 | cf_lgcvsymp17 | cf_lgcvsymp18 | cf_lgcvsymp19 | cf_lgcvsymp20 | cf_lgcvsymp21 | cf_lgcvsymp22 | cf_lgcvsymp26 | cf_lgcvsymp_oth | cf_tested | cf_testresult | cf_testwhen_d | cf_testwhen_m | cf_testwhen_y | cf_hadcovid | cf_testtrace | cf_traceinfo | cf_traceinfoeng | cf_traced | cf_contactcv19t1 | cf_contactcv19t5 | cf_contactcv19t2 | cf_contactcv19t3 | cf_contactcv19t4 | cf_riskcv19 | cf_smartphone | cf_smarttype | cf_smartmodel | cf_covidapp | cf_whynotapp1 | cf_whynotapp2 | cf_whynotapp3 | cf_whynotapp4 | cf_whynotapp5 | cf_whynotapp6 | cf_whynotapp7 | cf_whynotapp8 | cf_whynotapp9 | cf_whynotapp10 | cf_whynotapp11 | cf_whynotapp_oth | cf_whynotapporder | cf_covidappon | cf_covidappnot1 | cf_covidappnot2 | cf_covidappnot3 | cf_covidappnot_oth | cf_hhsymp | cf_hhsympwho_persona | cf_hhsympwho_personb | cf_hhsympwho_personc | cf_hhsympwho_persond | cf_hhsympwho_persone | cf_hhsympwho_personf | cf_hhsympwho_persong | cf_hhsympwho_personh | cf_hhsympwho_personi | cf_hhsympwho_personj | cf_hhsympwho_personk | cf_hhsympwho_personl | cf_hhsympwho_personm | cf_hhsympwho_personn | cf_hhsympwho_persono | cf_hhsympwho_personp | cf_hhsympwho_personq | cf_hhsympwho_personr | cf_hhsympwho_persons | cf_hhsympwho_persont | cf_hhsympwho_personu | cf_hhsympwho_personv | cf_hhsympwho_personw | cf_hhsympwho_personx | cf_hhsympwho_persony | cf_hhsympwho_none | cf_hhtest | cf_hhtestwho_persona | cf_hhtestwho_personb | cf_hhtestwho_personc | cf_hhtestwho_persond | cf_hhtestwho_persone | cf_hhtestwho_personf | cf_hhtestwho_persong | cf_hhtestwho_personh | cf_hhtestwho_personi | cf_hhtestwho_personj | cf_hhtestwho_personk | cf_hhtestwho_personl | cf_hhtestwho_personm | cf_hhtestwho_personn | cf_hhtestwho_persono | cf_hhtestwho_personp | cf_hhtestwho_personq | cf_hhtestwho_personr | cf_hhtestwho_persons | cf_hhtestwho_persont | cf_hhtestwho_personu | cf_hhtestwho_personv | cf_hhtestwho_personw | cf_hhtestwho_personx | cf_hhtestwho_persony | cf_hhtestwho_none | cf_hhresult_persona | cf_hhresult_personb | cf_hhresult_personc | cf_hhresult_persond | cf_hhresult_persone | cf_hhresult_personf | cf_hhresult_persong | cf_hhresult_personh | cf_hhresult_personi | cf_hhresult_personj | cf_hhresult_personk | cf_hhresult_personl | cf_hhresult_personm | cf_hhresult_personn | cf_hhresult_persono | cf_hhresult_personp | cf_hhresult_personq | cf_hhresult_personr | cf_hhresult_persons | cf_hhresult_persont | cf_hhresult_personu | cf_hhresult_personv | cf_hhresult_personw | cf_hhresult_personx | cf_hhresult_persony | cf_hhtestwhen_d_persona | cf_hhtestwhen_m_persona | cf_hhtestwhen_y_persona | cf_hhtestwhen_d_personb | cf_hhtestwhen_m_personb | cf_hhtestwhen_y_personb | cf_hhtestwhen_d_personc | cf_hhtestwhen_m_personc | cf_hhtestwhen_y_personc | cf_hhtestwhen_d_persond | cf_hhtestwhen_m_persond | cf_hhtestwhen_y_persond | cf_hhtestwhen_d_persone | cf_hhtestwhen_m_persone | cf_hhtestwhen_y_persone | cf_hhtestwhen_d_personf | cf_hhtestwhen_m_personf | cf_hhtestwhen_y_personf | cf_hhtestwhen_d_persong | cf_hhtestwhen_m_persong | cf_hhtestwhen_y_persong | cf_hhtestwhen_d_personh | cf_hhtestwhen_m_personh | cf_hhtestwhen_y_personh | cf_hhtestwhen_d_personi | cf_hhtestwhen_m_personi | cf_hhtestwhen_y_personi | cf_hhtestwhen_d_personj | cf_hhtestwhen_m_personj | cf_hhtestwhen_y_personj | cf_hhtestwhen_d_personk | cf_hhtestwhen_m_personk | cf_hhtestwhen_y_personk | cf_hhtestwhen_d_personl | cf_hhtestwhen_m_personl | cf_hhtestwhen_y_personl | cf_hhtestwhen_d_personm | cf_hhtestwhen_m_personm | cf_hhtestwhen_y_personm | cf_hhtestwhen_d_personn | cf_hhtestwhen_m_personn | cf_hhtestwhen_y_personn | cf_hhtestwhen_d_persono | cf_hhtestwhen_m_persono | cf_hhtestwhen_y_persono | cf_hhtestwhen_d_personp | cf_hhtestwhen_m_personp | cf_hhtestwhen_y_personp | cf_hhtestwhen_d_personq | cf_hhtestwhen_m_personq | cf_hhtestwhen_y_personq | cf_hhtestwhen_d_personr | cf_hhtestwhen_m_personr | cf_hhtestwhen_y_personr | cf_hhtestwhen_d_persons | cf_hhtestwhen_m_persons | cf_hhtestwhen_y_persons | cf_hhtestwhen_d_persont | cf_hhtestwhen_m_persont | cf_hhtestwhen_y_persont | cf_hhtestwhen_d_personu | cf_hhtestwhen_m_personu | cf_hhtestwhen_y_personu | cf_hhtestwhen_d_personv | cf_hhtestwhen_m_personv | cf_hhtestwhen_y_personv | cf_hhtestwhen_d_personw | cf_hhtestwhen_m_personw | cf_hhtestwhen_y_personw | cf_hhtestwhen_d_personx | cf_hhtestwhen_m_personx | cf_hhtestwhen_y_personx | cf_hhtestwhen_d_persony | cf_hhtestwhen_m_persony | cf_hhtestwhen_y_persony | cf_fluinvite | cf_hadflujab | cf_noflujab | cf_nofluinvite | cf_fluinvite50 | cf_flusoon | cf_vaxxer | cf_vaxno | cf_vaxwhy | cf_vaxpush1 | cf_vaxpush2 | cf_vaxpush3 | cf_ff_hcond1 | cf_ff_hcond2 | cf_ff_hcond3 | cf_ff_hcond4 | cf_ff_hcond5 | cf_ff_hcond6 | cf_ff_hcond7 | cf_ff_hcond8 | cf_ff_hcond10 | cf_ff_hcond11 | cf_ff_hcond12 | cf_ff_hcond13 | cf_ff_hcond14 | cf_ff_hcond15 | cf_ff_hcond16 | cf_ff_hcond18 | cf_ff_hcond19 | cf_ff_hcond21 | cf_ff_hcond22 | cf_ff_hcond23 | cf_ff_hcond24 | cf_ff_hcond27 | cf_ff_hcondhas | cf_ff_pregnow | cf_ff_stillpreg | cf_hcondnew_cv1 | cf_hcondnew_cv2 | cf_hcondnew_cv3 | cf_hcondnew_cv4 | cf_hcondnew_cv5 | cf_hcondnew_cv6 | cf_hcondnew_cv7 | cf_hcondnew_cv8 | cf_hcondnew_cv11 | cf_hcondnew_cv21 | cf_hcondnew_cv10 | cf_hcondnew_cv12 | cf_hcondnew_cv13 | cf_hcondnew_cv14 | cf_hcondnew_cv15 | cf_hcondnew_cv16 | cf_hcondnew_cv22 | cf_hcondnew_cv19 | cf_hcondnew_cv23 | cf_hcondnew_cv24 | cf_hcondnew_cv27 | cf_hcondnew_cv18 | cf_hcondnew_cv96 | cf_arthtypn | cf_cancertypn_cv1 | cf_cancertypn_cv2 | cf_cancertypn_cv3 | cf_cancertypn_cv4 | cf_cancertypn_cv5 | cf_cancertypn_cv6 | cf_cancertypn_cv8 | cf_cancertypn_cv7 | cf_mhealthtypn_cv2 | cf_mhealthtypn_cv3 | cf_mhealthtypn_cv4 | cf_mhealthtypn_cv5 | cf_mhealthtypn_cv6 | cf_mhealthtypn_cv8 | cf_mhealthtypn_cv9 | cf_mhealthtypn_cv10 | cf_mhealthtypn_cv11 | cf_mhealthtypn_cv12 | cf_mhealthtypn_cv13 | cf_mhealthtypn_cv14 | cf_mhealthtypn_cv15 | cf_mhealthtypn_cv16 | cf_mhealthtypn_cv17 | cf_mhealthtypn_cv18 | cf_mhealthtypn_cv19 | cf_mhealthtypn_cv20 | cf_hcond_treat1 | cf_hcond_treat2 | cf_hcond_treat3 | cf_hcond_treat4 | cf_hcond_treat5 | cf_hcond_treat6 | cf_treatment1 | cf_treatment2 | cf_treatment3 | cf_treatment4 | cf_treatment5 | cf_canceltreat | cf_nhsnowgp2 | cf_nhsnowpm2 | cf_nhsnowop2 | cf_nhsnowip2 | cf_nhsnow1112 | cf_chscnowpharm2 | cf_chscnowotcm2 | cf_chscnowcarer2 | cf_chscnowpsy2 | cf_pregnow | cf_stillpreg | cf_pregscan | cf_pregmidwife | cf_pregantenatal | cf_aidhh | cf_aidnum | cf_carehhc1 | cf_carehhc2 | cf_carehhc3 | cf_carehhc4 | cf_carehhc5 | cf_carehhc6 | cf_carehhwho1 | cf_carehhwho2 | cf_carehhwho3 | cf_carehhwho4 | cf_carehhwho5 | cf_carehhwho6 | cf_carehhwho7 | cf_carehhwho8 | cf_carehhsh | cf_aidhrs_cv | cf_respitenow | cf_caring | cf_carehow1 | cf_carehow2 | cf_carehow3 | cf_carehow4 | cf_carehow5 | cf_carehow6 | cf_carehow7 | cf_carehow8 | cf_carehow9 | cf_carehow10 | cf_carewho1 | cf_carewho2 | cf_carewho3 | cf_carewho4 | cf_carewho5 | cf_carewho6 | cf_carewho7 | cf_carewho8 | cf_help | cf_helpwhat1 | cf_helpwhat2 | cf_helpwhat3 | cf_helpwhat4 | cf_helpwhat5 | cf_helpwhat6 | cf_helpwhat7 | cf_helpwhat8 | cf_helpwhat9 | cf_helpwhat10 | cf_helpwho1 | cf_helpwho2 | cf_helpwho3 | cf_helpwho4 | cf_helpwho5 | cf_helpwho6 | cf_helpwho7 | cf_helpwho8 | cf_sclonely_cv | cf_f2fcontact | cf_f2fcontfreq | cf_phcontact | cf_smcontact | cf_whymove1 | cf_whymove2 | cf_whymove3 | cf_whymove4 | cf_whymove5 | cf_whymove6 | cf_whymove7 | cf_whymove8 | cf_whymove9 | cf_whymove10 | cf_whymove11 | cf_whymove12 | cf_whymove13 | cf_hsownd_cv | cf_garden1 | cf_garden2 | cf_garden3 | cf_garden4 | cf_garden5 | cf_garden6 | cf_deskspace | cf_pcnet | cf_expmove | cf_whyexpmove1 | cf_whyexpmove2 | cf_whyexpmove3 | cf_whyexpmove4 | cf_whyexpmove5 | cf_whyexpmove6 | cf_whyexpmove7 | cf_whyexpmove8 | cf_whyexpmove9 | cf_whyexpmove10 | cf_whyexpmove11 | cf_whyexpmove12 | cf_whyexpmove13 | cf_ff_semp | cf_ff_sempderived | cf_ff_hours | cf_ff_furlough | cf_ff_stillfurl | cf_ff_sempgovt | cf_ff_blwork | cf_sempchk | cf_semp | cf_sempderived | cf_hours | cf_hrschange112 | cf_hrschange11 | cf_hrschange12 | cf_hrschange13 | cf_hrschange14 | cf_hrschange15 | cf_hrschange116 | cf_hrschange16 | cf_hrschange113 | cf_hrschange17 | cf_hrschange18 | cf_hrschange19 | cf_hrschange114 | cf_hrschange110 | cf_hrschange115 | cf_hrschange111 | cf_hrschange28 | cf_hrschange21 | cf_hrschange22 | cf_hrschange23 | cf_hrschange24 | cf_hrschange25 | cf_hrschange29 | cf_hrschange26 | cf_hrschange210 | cf_hrschange27 | cf_hrschange315 | cf_hrschange31 | cf_hrschange32 | cf_hrschange33 | cf_hrschange34 | cf_hrschange35 | cf_hrschange319 | cf_hrschange36 | cf_hrschange316 | cf_hrschange37 | cf_hrschange38 | cf_hrschange39 | cf_hrschange310 | cf_hrschange311 | cf_hrschange312 | cf_hrschange317 | cf_hrschange313 | cf_hrschange318 | cf_hrschange314 | cf_hrschangeup11 | cf_hrschangeup12 | cf_hrschangeup13 | cf_hrschangeup14 | cf_hrschangeup15 | cf_hrschangeup16 | cf_hrschangeup17 | cf_hrschangeup18 | cf_hrschangeup19 | cf_hrschangeup110 | cf_hrschangeup111 | cf_hrschangeup112 | cf_hrschangeup113 | cf_stillfurl | cf_supprob6 | cf_supprob8 | cf_sempgovt2 | cf_netpay_amount | cf_netpay_period | cf_grosspay_amount | cf_grosspay_period | cf_hhearners | cf_hhearn_amount | cf_hhearn_period | cf_hhincome_amount | cf_hhincome_period | cf_ghhincome_amount | cf_ghhincome_period | cf_wah | cf_wktrv_cv1 | cf_wktrv_cv2 | cf_wktrv_cv3 | cf_wktrv_cv4 | cf_wktrv_cv5 | cf_wktrv_cv6 | cf_wktrv_cv7 | cf_wktrv_cv8 | cf_wktrv_cv9 | cf_wktrv_cv10 | cf_wktrv_cv11 | cf_wktrv_cv12 | cf_wktrvfar_cv | cf_trcarfq_cv | cf_trbikefq_cv | cf_trwalkfq | cf_trbusfq_cv | cf_trtrnfq_cv | cf_trtubefq | cf_ff_ucredit | cf_ff_morhol | cf_ff_hsownd_cv | cf_ff_credithol | cf_ucreditb65 | cf_ucredit2b65 | cf_ucreditadvance65 | cf_benefitsamt65 | cf_transfers | cf_transfmade1 | cf_transfmade2 | cf_transfmade3 | cf_transfmade4 | cf_transfmade5 | cf_transfmade6 | cf_transfmade7 | cf_transfrec1 | cf_transfrec2 | cf_transfrec3 | cf_transfrec4 | cf_transfrec5 | cf_transfrec6 | cf_transfrec7 | cf_transfout | cf_transfin | cf_xphs_cv | cf_morhol3 | cf_renthol | cf_xpbills_cv | cf_credithol | cf_creditholend | cf_creditholwhich1 | cf_creditholwhich2 | cf_creditholwhich3 | cf_creditholwhich4 | cf_creditholwhich5 | cf_inoutflows1 | cf_inoutflows2 | cf_inoutflows9 | cf_inoutflows3 | cf_inoutflows4 | cf_inoutflows5 | cf_inoutflows6 | cf_inoutflows10 | cf_inoutflows7 | cf_inoutflows8 | cf_save_cv | cf_saved_cv | cf_debtnonmort | cf_debtamt | cf_debt2 | cf_debt3 | cf_spend | cf_ff_mpcalloc | cf_finnow | cf_finfut_cv3 | cf_jobsec | cf_finsec | cf_mpc1 | cf_mpc2 | cf_mpc31 | cf_mpc32 | cf_mpc33 | cf_mpc34 | cf_mpc35 | cf_mpc1b | cf_mpc2b | cf_mpc3b1 | cf_mpc3b2 | cf_mpc3b3 | cf_mpc3b4 | cf_scopngbhh_cv | cf_nbrcoh3 | cf_nbrcoh2 | cf_nbrcoh4 | cf_scopngbhg | cf_crrace_cv | cf_num418 | cf_ch418doba_y | cf_ch418dobb_y | cf_ch418dobc_y | cf_ch418dobd_y | cf_ch418dobe_y | cf_childage_childa | cf_childage_childb | cf_childage_childc | cf_childage_childd | cf_childage_childe | cf_schoollw_childa | cf_schoollw_childb | cf_schoollw_childc | cf_schoollw_childd | cf_schoollw_childe | cf_schoollwdys_childa | cf_schoollwdys_childb | cf_schoollwdys_childc | cf_schoollwdys_childd | cf_schoollwdys_childe | cf_schoollwhrs_childa | cf_schoollwhrs_childb | cf_schoollwhrs_childc | cf_schoollwhrs_childd | cf_schoollwhrs_childe | cf_schoollwgo_childa | cf_schoollwgo_childb | cf_schoollwgo_childc | cf_schoollwgo_childd | cf_schoollwgo_childe | cf_schoolgodys_childa | cf_schoolgodys_childb | cf_schoolgodys_childc | cf_schoolgodys_childd | cf_schoolgodys_childe | cf_schoolgohrs_childa | cf_schoolgohrs_childb | cf_schoolgohrs_childc | cf_schoolgohrs_childd | cf_schoolgohrs_childe | cf_schoolwork_childa | cf_schoolwork_childb | cf_schoolwork_childc | cf_schoolwork_childd | cf_schoolwork_childe | cf_lessonsoff_childa | cf_lessonsoff_childb | cf_lessonsoff_childc | cf_lessonsoff_childd | cf_lessonsoff_childe | cf_lessonson_childa | cf_lessonson_childb | cf_lessonson_childc | cf_lessonson_childd | cf_lessonson_childe | cf_hstime2_childa | cf_hstime2_childb | cf_hstime2_childc | cf_hstime2_childd | cf_hstime2_childe | cf_hshelp2_childa | cf_hshelp2_childb | cf_hshelp2_childc | cf_hshelp2_childd | cf_hshelp2_childe | cf_tutoring1_childa | cf_tutoring2_childa | cf_tutoring3_childa | cf_tutoring1_childb | cf_tutoring2_childb | cf_tutoring3_childb | cf_tutoring1_childc | cf_tutoring2_childc | cf_tutoring3_childc | cf_tutoring1_childd | cf_tutoring2_childd | cf_tutoring3_childd | cf_tutoring1_childe | cf_tutoring2_childe | cf_tutoring3_childe | cf_remedials_childa | cf_remedials_childb | cf_remedials_childc | cf_remedials_childd | cf_remedials_childe | cf_academprg_childa | cf_academprg_childb | cf_academprg_childc | cf_academprg_childd | cf_academprg_childe | cf_cospace1_childa | cf_cospace1_childb | cf_cospace1_childc | cf_cospace1_childd | cf_cospace1_childe | cf_cospace2_childa | cf_cospace2_childb | cf_cospace2_childc | cf_cospace2_childd | cf_cospace2_childe | cf_cospace3_childa | cf_cospace3_childb | cf_cospace3_childc | cf_cospace3_childd | cf_cospace3_childe | cf_cospace4_childa | cf_cospace4_childb | cf_cospace4_childc | cf_cospace4_childd | cf_cospace4_childe | cf_cospace5_childa | cf_cospace5_childb | cf_cospace5_childc | cf_cospace5_childd | cf_cospace5_childe | cf_sclfsato_cv | cf_scghqa | cf_scghqb | cf_scghqc | cf_scghqd | cf_scghqe | cf_scghqf | cf_scghqg | cf_scghqh | cf_scghqi | cf_scghqj | cf_scghqk | cf_scghql | cf_incentives | cf_noemailvoucher | cf_scghq1_dv | cf_scghq2_dv | cf_outcome | cf_lastq | cf_lastmodule | cf_link | cf_surveystart | cf_surveyend | cf_surveytime | cf_tsidcheckst | cf_tsidcheckend | cf_tshhrelst | cf_tshhrelend | cf_tssahst | cf_tssahend | cf_tscovidst | cf_tscovidend | cf_tshhcvst | cf_tshhcvend | cf_tsflust | cf_tsfluend | cf_tslthealthst | cf_tslthealthend | cf_tscaringhhst | cf_tscaringhhend | cf_tscareexhhst | cf_tscareexhhend | cf_tslonelyst | cf_tslonelyend | cf_tscffst | cf_tscffend | cf_tshsingst | cf_tshsingend | cf_tsempst | cf_tsempend | cf_tsttwst | cf_tsttwend | cf_tstranspst | cf_tstranspend | cf_tsfinst | cf_tsfinend | cf_tsfinsecst | cf_tsfinsecend | cf_tsnbhdst | cf_tsnbhdend | cf_tsnovschst | cf_tsnovschend | cf_tslfsatst | cf_tslfsatend | cf_tsghqst | cf_tsghqend | cf_tsclosest | cf_tscloseend | cf_screenres | cf_browserres | cf_useragentstring | cf_ff_prevsurv | cf_ff_intd | cf_ff_intm | cf_ff_inty | cf_ff_country | cf_gor_dv | cf_aid_dv | cf_betaindin_xw | cf_betaindin_xw_t | cf_betaindin_lw | cf_betaindin_lw_t1 | cf_betaindin_lw_t2 |
|---|
USocietyCovid.shape
(12035, 916)
USocietyCovid.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12035 entries, 0 to 12034
Columns: 916 entries, pidp to cf_betaindin_lw_t2
dtypes: float64(10), int64(855), object(51)
memory usage: 84.1+ MB
Defining Output and Input variables¶
Here are the Output and Input data features we will use in this session.
Outcome: Output (Y)¶
Description |
Variable |
Values |
|---|---|---|
Likelihood of taking up a coronavirus vaccination |
cf_vaxxer |
1 = Very likely, 2 = Likely, 3 = Unlikely, 4 = Very unlikely |
Predictors: Input features (X)¶
We select 4 (demographic and health-related) variables as examples only, no prior literature or expert knowledge is considered. We will discuss the role of prior literature and expert knowledge in the process of variable selection when we learn causal inference approaches.
Description |
Variable |
Values |
|---|---|---|
Age |
cf_age |
Integer values (whole numbers) |
Respondent sex |
cf_sex_cv |
1 = Male, 2 = Female, 3 = Prefer not to say |
General health |
cf_scsf1 |
1 = Excellent, 2 = Very good, 3 = Good, 4 = Fair, 5 = Poor |
At risk of serious illness from Covid-19 |
cf_clinvuln_dv |
0 = no risk (not clinically vulnerable), 1 = moderate risk (clinically vulnerable), 2 = high risk (clinically extremely vulnerable) |
Data wrangling¶
# Select output y and input X variables
USocietyCovid = USocietyCovid[
["cf_vaxxer", "cf_age", "cf_sex_cv", "cf_scsf1", "cf_clinvuln_dv"]
]
USocietyCovid.head()
| cf_vaxxer | cf_age | cf_sex_cv | cf_scsf1 | cf_clinvuln_dv | |
|---|---|---|---|---|---|
| 0 | 2 | 37 | 2 | 2 | 0 |
| 1 | 3 | 35 | 1 | 4 | 0 |
| 2 | 3 | 55 | 2 | 2 | 0 |
| 3 | 1 | 38 | 1 | 3 | 1 |
| 4 | 1 | 67 | 2 | 2 | 0 |
import seaborn as sns
sns.set_context("notebook", font_scale=1.5)
%matplotlib inline
fig = sns.catplot(
x="cf_vaxxer",
kind="count",
height=6,
aspect=1.5,
palette="ch:.25",
data=USocietyCovid,
)
# Tweak the plot
(
fig.set_axis_labels(
"Likelihood of taking up a coronavirus vaccination", "Frequency"
)
.set_xticklabels(
[
"missing",
"inapplicable",
"refusal",
"don't know",
"Very likely",
"Likely",
"Unlikely",
"Very unlikely",
]
)
.set_xticklabels(rotation=45)
)
<seaborn.axisgrid.FacetGrid at 0x7f9209efc670>
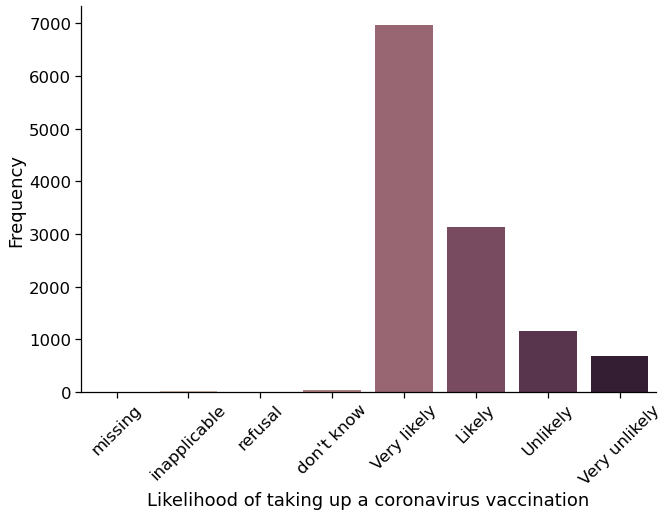
Missing observations in Understanding Society are indicated by negative values. Let’s convert negative values to NaN using the function mask in pandas. An alternative approach would be to reload the data using the Pandas read_csv() function and provide the negative values as an argument to the parameter na_values, as a result of which Pandas will recognise these values as NaN.
# The function 'mask' in pandas replaces values where a condition is met.
USocietyCovid = USocietyCovid.mask(USocietyCovid < 0)
# Alternatively, you could replace negative values with another value, e.g., 0,
# using the code USocietyCovid.mask(USocietyCovid < 0, 0).
USocietyCovid
| cf_vaxxer | cf_age | cf_sex_cv | cf_scsf1 | cf_clinvuln_dv | |
|---|---|---|---|---|---|
| 0 | 2.0 | 37 | 2 | 2.0 | 0.0 |
| 1 | 3.0 | 35 | 1 | 4.0 | 0.0 |
| 2 | 3.0 | 55 | 2 | 2.0 | 0.0 |
| 3 | 1.0 | 38 | 1 | 3.0 | 1.0 |
| 4 | 1.0 | 67 | 2 | 2.0 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 12030 | 1.0 | 57 | 1 | 2.0 | 0.0 |
| 12031 | 2.0 | 70 | 2 | 3.0 | 1.0 |
| 12032 | 2.0 | 64 | 1 | 2.0 | 0.0 |
| 12033 | 4.0 | 31 | 1 | 1.0 | 0.0 |
| 12034 | 3.0 | 41 | 2 | 3.0 | 0.0 |
12035 rows × 5 columns
# Remove NaN
USocietyCovid = USocietyCovid[
["cf_vaxxer", "cf_age", "cf_sex_cv", "cf_scsf1", "cf_clinvuln_dv"]
].dropna()
USocietyCovid
| cf_vaxxer | cf_age | cf_sex_cv | cf_scsf1 | cf_clinvuln_dv | |
|---|---|---|---|---|---|
| 0 | 2.0 | 37 | 2 | 2.0 | 0.0 |
| 1 | 3.0 | 35 | 1 | 4.0 | 0.0 |
| 2 | 3.0 | 55 | 2 | 2.0 | 0.0 |
| 3 | 1.0 | 38 | 1 | 3.0 | 1.0 |
| 4 | 1.0 | 67 | 2 | 2.0 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 12030 | 1.0 | 57 | 1 | 2.0 | 0.0 |
| 12031 | 2.0 | 70 | 2 | 3.0 | 1.0 |
| 12032 | 2.0 | 64 | 1 | 2.0 | 0.0 |
| 12033 | 4.0 | 31 | 1 | 1.0 | 0.0 |
| 12034 | 3.0 | 41 | 2 | 3.0 | 0.0 |
11930 rows × 5 columns
# Plot the new cf_vaxxer (vaccination likelihood) variable
fig = sns.catplot(
x="cf_vaxxer",
kind="count",
height=6,
aspect=1.5,
palette="ch:.25",
data=USocietyCovid,
)
# Tweak the plot
(
fig.set_axis_labels(
"Likelihood of taking up a coronavirus vaccination", "Frequency"
)
.set_xticklabels(["Very likely", "Likely", "Unlikely", "Very unlikely"])
.set_xticklabels(rotation=45)
)
<seaborn.axisgrid.FacetGrid at 0x7f92284700d0>
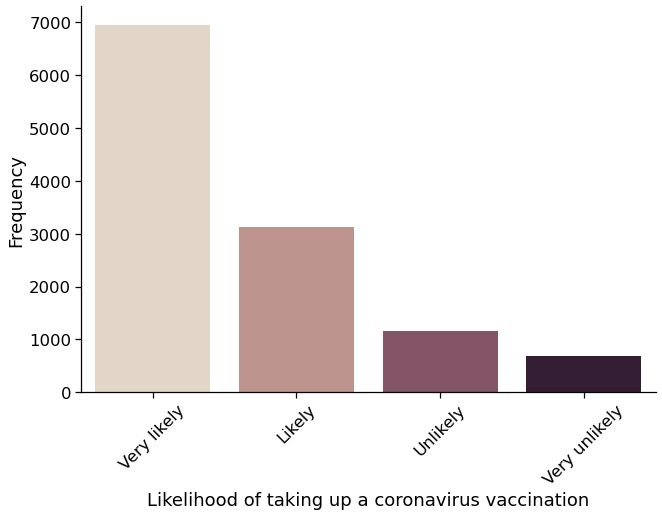
To simplify the problem, we will recode cf_vaxxer (vaccination likelihood) variable into a binary variable where 1 refers to ‘Likely to take up a Covid-19 vaccine’ and 2 refers to ‘Unlikely to take up a Covid-19 vaccine’. To achieve this, we use the replace() method which replaces a set of values we specify (in our case, [1,2,3,4]) with another set of values we specify (in our case, [1,1,0,0]).
# Recode cf_vaxxer into a binary variable
USocietyCovid["cf_vaxxer"] = USocietyCovid["cf_vaxxer"].replace(
[1, 2, 3, 4], [1, 1, 0, 0]
)
USocietyCovid.head()
| cf_vaxxer | cf_age | cf_sex_cv | cf_scsf1 | cf_clinvuln_dv | |
|---|---|---|---|---|---|
| 0 | 1.0 | 37 | 2 | 2.0 | 0.0 |
| 1 | 0.0 | 35 | 1 | 4.0 | 0.0 |
| 2 | 0.0 | 55 | 2 | 2.0 | 0.0 |
| 3 | 1.0 | 38 | 1 | 3.0 | 1.0 |
| 4 | 1.0 | 67 | 2 | 2.0 | 0.0 |
# Plot the binary cf_vaxxer (vaccination likelihood) variable
fig = sns.catplot(
x="cf_vaxxer",
kind="count",
height=6,
aspect=1.5,
palette="ch:.25",
data=USocietyCovid,
)
# Tweak the plot
(
fig.set_axis_labels(
"Likelihood of taking up a coronavirus vaccination", "Frequency"
)
.set_xticklabels(["Unlikely", "Likely"])
.set_xticklabels(rotation=45)
)
<seaborn.axisgrid.FacetGrid at 0x7f92586612b0>

USocietyCovid.groupby("cf_vaxxer").count()
| cf_age | cf_sex_cv | cf_scsf1 | cf_clinvuln_dv | |
|---|---|---|---|---|
| cf_vaxxer | ||||
| 0.0 | 1837 | 1837 | 1837 | 1837 |
| 1.0 | 10093 | 10093 | 10093 | 10093 |
USocietyCovid.shape[0]
11930
# 84.6% of respondents very likely or likely to take up a Covid vaccine
# and 15.4% very unlikely or unlikely
USocietyCovid.groupby("cf_vaxxer").count() / USocietyCovid.shape[0]
| cf_age | cf_sex_cv | cf_scsf1 | cf_clinvuln_dv | |
|---|---|---|---|---|
| cf_vaxxer | ||||
| 0.0 | 0.153982 | 0.153982 | 0.153982 | 0.153982 |
| 1.0 | 0.846018 | 0.846018 | 0.846018 | 0.846018 |
So far, we have described our outcome variable to make sense of the task but we have neither looked at the predictor variables nor examined any relationships between predictor variables and outcomes. It is a good practice to first split the data into training set and test set and only then explore predictors and relationships in the training set.
Overfitting and data splitting¶
The problem of model overfitting¶
Overfitting occurs when model captures ‘noise’ in a specific sample while failing to recognise general patterns across samples. As a result of overfitting, the model produces accurate predictions for examples from the sample at hand but will predict poorly new examples the model has never seen.
Training set, Validation set, and Test set¶
To avoid overfitting, data is typically split into three groups:
Training set — used to train models
Validation set — used to tune the model and estimate model performance/accuracy for best model selection
Test set - used to evaluate the generalisability of the model to new observations the model has never seen
If your data set is not large enough, a possible strategy, which we will use here, is to split the data into training set and test set, and use cross-validation on the training set to evaluate our models’ performance/accuracy. We will use 2/3 of the data to train the predictive model and the remaining 1/3 to create the test set.
# Split train and test data
from sklearn.model_selection import train_test_split
# Outcome variable
y = USocietyCovid[["cf_vaxxer"]]
# Predictor variables
X = USocietyCovid[["cf_age", "cf_sex_cv", "cf_scsf1", "cf_clinvuln_dv"]]
# Split data into training set and test set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, stratify=y, random_state=0
)
print("Train data", X_train.shape, "\n" "Test data", X_test.shape)
Train data (7993, 4)
Test data (3937, 4)
Preprocessing the training data set¶
Categorical predictors — dummy variables¶
Categorical variables are often encoded using numeric values. For example, Respondent sex is recorded as 1 = Men, 2 = Female, 3 = Prefer not to say. The numeric values can be ‘misinterpreted’ by the algorithms — the value of 1 is obviously less than the value of 3 but that does not correspond to real-world numerical differences.
A solution is to convert categorical predictors into dummy variables. Basically, each category value is converted into a new column and assigns a 1 or 0 (True/False) values using the function get_dummies in pandas. The function creates dummy/indicator variables that contain value of 1 or 0.
The Respondent sex variable is converted below is three columns of 1s or 0s corresponding to the respective value.
# Use get_dummies to convert the Respondent sex categorical variable into
# 3 dummy/indicator variables
X_train_predictors = pd.get_dummies(X_train, columns=["cf_sex_cv"])
X_train_predictors.head()
| cf_age | cf_scsf1 | cf_clinvuln_dv | cf_sex_cv_1 | cf_sex_cv_2 | cf_sex_cv_3 | |
|---|---|---|---|---|---|---|
| 994 | 28 | 2.0 | 0.0 | 0 | 1 | 0 |
| 11376 | 41 | 5.0 | 0.0 | 0 | 1 | 0 |
| 9730 | 77 | 3.0 | 1.0 | 0 | 1 | 0 |
| 8235 | 41 | 3.0 | 2.0 | 0 | 1 | 0 |
| 1406 | 60 | 2.0 | 0.0 | 0 | 1 | 0 |
# Create two DataFrames, one for numerical variables
# and one for categorical variables
X_train_predictors_cat = X_train_predictors[
["cf_sex_cv_1", "cf_sex_cv_2", "cf_sex_cv_3"]
]
X_train_predictors_cont = X_train_predictors[["cf_age", "cf_scsf1", "cf_clinvuln_dv"]]
Continuous predictors — standardisation¶
We standardise the continuous input variables.
# Standardise the predictors using the StandardScaler function in sklearn
from sklearn.preprocessing import StandardScaler # For standartising data
scaler = StandardScaler() # Initialising the scaler using the default arguments
X_train_predictors_cont_scale = scaler.fit_transform(
X_train_predictors_cont
) # Fit to continuous input variables and return the standardised dataset
X_train_predictors_cont_scale
array([[-1.65608796, -0.56081614, -0.80754698],
[-0.84497135, 2.64868513, -0.80754698],
[ 1.40119771, 0.50901761, 0.81873748],
...,
[-0.96975852, -1.6306499 , -0.80754698],
[ 0.46529394, 0.50901761, 2.44502193],
[ 0.77726186, 0.50901761, 0.81873748]])
Combine categorical and continuous predictors into one data array¶
# Use the concatenate function in Numpy to combine all variables
# (both categorical and continuous predictors) in one array
X_train_preprocessed = np.concatenate(
[X_train_predictors_cont_scale, X_train_predictors_cat], axis=1
)
X_train_preprocessed
array([[-1.65608796, -0.56081614, -0.80754698, 0. , 1. ,
0. ],
[-0.84497135, 2.64868513, -0.80754698, 0. , 1. ,
0. ],
[ 1.40119771, 0.50901761, 0.81873748, 0. , 1. ,
0. ],
...,
[-0.96975852, -1.6306499 , -0.80754698, 0. , 1. ,
0. ],
[ 0.46529394, 0.50901761, 2.44502193, 0. , 1. ,
0. ],
[ 0.77726186, 0.50901761, 0.81873748, 1. , 0. ,
0. ]])
X_train_preprocessed.shape
(7993, 6)
Unbalance class problem¶
In the case of the vaccination likelihood question, one of the classes (likely to vaccinate) has a significantly greater proportion of cases (84.6%) than the other case (unlikely to vaccinate) (15.4%). We therefore face an unbalanced class problem.
Different methods to mitigate the problem exist. We will use a method called ADASYN: Adaptive Synthetic Sampling Method for Imbalanced Data. The method oversamples the minority class in the training data set until both classes have an equal number of observations. Hence, the data set we use to train our models contains two balanced classes.
from imblearn.over_sampling import ADASYN
# Initialization of the ADASYN resampling method; set random_state for reproducibility
adasyn = ADASYN(random_state=0)
# Fit the ADASYN resampling method to the train data
X_train_balance, y_train_balance = adasyn.fit_resample(X_train_preprocessed, y_train)
The resulting X_train_balance and y_train_balance now include both the original data and the resampled data. The y_train_balance now includes an almost equal number of labels for each class.
# Now that the two classes are balanced, the train data
# is ~14K observations, greater than the original ~8K.
X_train_balance.shape
(13611, 6)
Hands-on mini-exercise¶
Verify that after the oversampling the y_train_balance data object contains indeed approximately equal number of observations for both classes, those likely to vaccinate (1) and those unlikely to vaccinate (0).
Note that y_train_balance is a NumPy array. You can check that on your own using the function type(), for example: type(y_train).
(y_train_balance == 0).sum()
cf_vaxxer 6849
dtype: int64
(y_train_balance == 1).sum()
cf_vaxxer 6762
dtype: int64
Train models on training data¶
We fit two classifiers — k-Nearest Neighbours (k-NN) and Logistic Regression — on the training data. The k-Nearest Neighbours classifier (k-NN) and Logistic Regression classifier are two widely used classifiers. Our focus is on the end-to-end workflow so we do not discuss the workings of the two classifiers in detail. To learn more about the two classifiers, see Python Data Science Handbook by Jake VanderPlas (on k-NN) and the DataCamp course Supervised Learning with scikit-learn.
In the models below, we use the default hyperparameters (hyperparameter are parameters that are not learned from data but are set by the researcher to guide the learning process) for both classifiers.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
# Create an instance of k-nearest neighbors (k-NN) classifier.
# We set the hyperparameter n_neighbors=5 meaning that
# the label of an unknown respondent (0 or 1) is a function of
# the labels of its five closest training respondents.
kNN_Classifier = KNeighborsClassifier(n_neighbors=5)
# Create an instance of Logistic Regression Classifier
LogReg_Classifier = LogisticRegression()
# Fit both models to the training data
kNN_Classifier.fit(X_train_balance, y_train_balance.cf_vaxxer)
LogReg_Classifier.fit(X_train_balance, y_train_balance.cf_vaxxer)
LogisticRegression()
Model evaluation using Cross-validation¶
Now that your two models are fitted, you can evaluate the accuracy of their prediction. In older approaches, the prediction accuracy is often calculated on the same set of training data used to fit the model. The problem of such an approach is that the model can ‘memorise’ the training data and show high prediction accuracy on that data set while failing to perform well on new data. For this reason, approaches in data science, and machine learning in particular, prefer to evaluate the prediction accuracy of a model on new data that has not been used in training the model.
The cross-validation technique¶
Cross-validation is a technique for assessing accuracy of model prediction without relying on in-sample prediction. We will split our training set into k equal folds or parts. The number of folds can differ but for simplicity we will consider 5-fold cross-validation. How does 5-fold cross-validation work? While keeping aside one fold (or part), we fit the model with the remaining four folds and use the fitted model to predict outcomes of observations in fold one and on this basis compute model prediction accuracy. We repeat the procedure for all 5 folds or parts of the data and compute the average prediction accuracy.
Metrics to evaluate model performance¶
Many metrics to evaluate model performance exist. We evaluate model performance using the accuracy score. The accuracy score is the simplest metric for evaluating classification models. Simply put, accuracy is the proportion of predictions our model got right. Keep in mind, however, that because of the unbalanced class problem, accuracy may not be the best metric in our case. Because one of our classes accounts for 84.6% of the cases, even a model that uniformly predicts that all respondents are likely to take up the vaccine will obtain very high accuracy of 0.846 while being useless for identifying respondents who are unlikely to take up the vaccine. We will return to this problem shortly.
# Import the function cross_val_score() which performs
# cross-validation and evaluates the model using a score.
# Many scores are available to evaluate a classification mdoel,
# as a starting point, we select the simplest one called accuracy.
from sklearn.model_selection import cross_val_score
# Evaluate the kNN_Classifier model via 5-fold cross-validation
kNN_score = cross_val_score(
kNN_Classifier, X_train_balance, y_train_balance.cf_vaxxer, cv=5, scoring="accuracy"
)
kNN_score
array([0.6232097 , 0.65686995, 0.64070536, 0.65980896, 0.64731815])
# Take the mean across the five accuracy scores
kNN_score.mean() * 100
64.55824239753719
# Repeat for our logistic regression model
LogReg_score = cross_val_score(
LogReg_Classifier,
X_train_balance,
y_train_balance.cf_vaxxer,
cv=5,
scoring="accuracy",
)
LogReg_score.mean() * 100
62.21431553077533
The output from the cross-validation technique shows that the performance of our two models is comparable as measured by the accuracy score.
At this stage, we could fine-tune model hyperparameters — i.e., parameters that the model does not learn from data, e.g., the number of k neighbours in the k-NN algorithm — and re-evaluate model performance. During the process of model validation, we do not use the test data. Once we are happy with how our model(s) perform, we test the model on unseen data.
Testing model accuracy on new data¶
Before we test the accuracy of our model on the test data set, we preprocess the test data set using the same procedure we used to preprocess the training data.
Preprocessing the test data set¶
# Use get_dummies to convert the respondent sex categorical variable
# into 3 dummy/indicator variables.
X_test_predictors = pd.get_dummies(X_test, columns=["cf_sex_cv"])
# Create two DataFrames, one for quantitative variables and one for qualitative variables
X_test_predictors_cat = X_test_predictors[["cf_sex_cv_1", "cf_sex_cv_2", "cf_sex_cv_3"]]
X_test_predictors_cont = X_test_predictors[["cf_age", "cf_scsf1", "cf_clinvuln_dv"]]
# Standardise the predictors using the StandardScaler function in sklearn
scaler = StandardScaler() # Initialising the scaler using the default arguments
X_test_predictors_cont_scale = scaler.fit_transform(
X_test_predictors_cont
) # Fit to continuous input variables and return the standardised dataset
# Use the concatenate function in Numpy to combine all variables
# (both categorical and continuous predictors) in one array
X_test_preprocessed = np.concatenate(
[X_test_predictors_cont_scale, X_test_predictors_cat], axis=1
)
X_test_preprocessed
array([[ 0.44686144, -1.63480238, -0.82552056, 1. , 0. ,
0. ],
[-0.41738323, -0.58244513, -0.82552056, 0. , 1. ,
0. ],
[-0.35565147, -0.58244513, -0.82552056, 1. , 0. ,
0. ],
...,
[ 0.01473911, -0.58244513, -0.82552056, 1. , 0. ,
0. ],
[ 1.37283788, 0.46991213, 0.7914319 , 0. , 1. ,
0. ],
[-0.47911499, -1.63480238, -0.82552056, 1. , 0. ,
0. ]])
Predicting vaccine hesitancy¶
Use the predict function to predict who is likely to take up the COVID-19 vaccine or not using the test data.
y_pred_kNN = kNN_Classifier.predict(X_test_preprocessed)
y_pred_LogReg = LogReg_Classifier.predict(X_test_preprocessed)
y_pred_LogReg
array([1., 0., 1., ..., 1., 1., 1.])
Model evaluation on test data¶
Let’s evaluate the performance of our models predicting vaccination willingness using accuracy metric.
# Evaluate performance using the accuracy score for the logistic regresson model
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred_LogReg)
0.6245872491744984
# Evaluate performance using the accuracy score for the k-nearest neighbors model
accuracy_score(y_test, y_pred_kNN)
0.5044450088900178
The accuracy scores are slightly lower on the test set compared to the accuracy score on the training set, indicating that the data split methodology mitigates the risk of overfitting.
Accuracy is a good metric when the positive class and the negative class are balanced. However, when one of the classes is a majority, as in our case, then a model can achieve a high accuracy by just predicting all observations to be the majority class. However, this is not what we want. In fact, in order to inform an information campaign about vaccination, we are more interested in predicting the minority class, people that are unlikely to take up the vaccine.
We can use a confusion matrix to further evaluate the performance of our classification models. The confusion matrix shows the number of respondents known to be in group 0 (unlikely to vaccinate) or 1 (likely to vaccinate) and predicted to be in group 0 or 1, respectively.
The confusion matrix below shows that the logistic model predicts 393 out of the 606 respondents who are unlikely to vaccinate. The model does much better job predicting respondents that are likely to vaccinate, 2066 out of 3331 respondents in the test data set.
# Confusion matrix for the logistic regression model
# plotted via the Pandas crosstab() function
pd.crosstab(
y_test.cf_vaxxer,
y_pred_LogReg,
rownames=["Actual"],
colnames=["Predicted"],
margins=True,
)
| Predicted | 0.0 | 1.0 | All |
|---|---|---|---|
| Actual | |||
| 0.0 | 393 | 213 | 606 |
| 1.0 | 1265 | 2066 | 3331 |
| All | 1658 | 2279 | 3937 |
What do the numbers in the confusion matrix mean?
True positive - our model correctly predicts the positive class (likely to vaccinate)
True negative - our model correctly predicts the negative class (unlikely to vaccinate)
False positive - our model incorrectly predicts the positive class
False negative - our model incorrectly predicts the negative class
# Here is another representation of the confusion matrix
# using the scikit-learn `confusion_matrix` function
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred_LogReg)
array([[ 393, 213],
[1265, 2066]])
# The function ravel() flattens the confusion matrix
tn, fp, fn, tp = confusion_matrix(y_test, y_pred_LogReg).ravel()
print(
"True negative = ",
tn,
"\nFalse positive = ",
fp,
"\nFalse negative = ",
fn,
"\nTrue positive = ",
tp,
)
True negative = 393
False positive = 213
False negative = 1265
True positive = 2066
For the k-nearest neighbors model, the confusion matrix below shows that the k-NN model predicts 316 out of the 606 respondents who are unlikely to vaccinate (the logistic regression model predicts more accurately those unlikely to vaccinate). The model does not predicts well respondents that are likely to vaccinate, 1670 out of 3331 respondents in the test data set.
Recall that we are less interested in predicting the majority class (likely to vaccinate). Instead, we are interested in predicting the minority class (unlikely to vaccinate) so that the results can inform an information campaign among people that are unlikely to vaccinate.
# Confusion matrix for the k-nearest neighbors model
# plotted via pandas function crosstab
pd.crosstab(
y_test.cf_vaxxer,
y_pred_kNN,
rownames=["Actual"],
colnames=["Predicted"],
margins=True,
)
| Predicted | 0.0 | 1.0 | All |
|---|---|---|---|
| Actual | |||
| 0.0 | 316 | 290 | 606 |
| 1.0 | 1661 | 1670 | 3331 |
| All | 1977 | 1960 | 3937 |
Instead of relying on a single metric, it is often helpful (if not confusing) to compare various metrics. You can use the scikit-learn function classification_report to calculate various classification metrics, including precision and recall.
from sklearn.metrics import classification_report
# Various metrics for the logistic regression model
print(classification_report(y_test, y_pred_LogReg))
precision recall f1-score support
0.0 0.24 0.65 0.35 606
1.0 0.91 0.62 0.74 3331
accuracy 0.62 3937
macro avg 0.57 0.63 0.54 3937
weighted avg 0.80 0.62 0.68 3937
# Various metrics for the k-nearest neighbors model
print(classification_report(y_test, y_pred_kNN))
precision recall f1-score support
0.0 0.16 0.52 0.24 606
1.0 0.85 0.50 0.63 3331
accuracy 0.50 3937
macro avg 0.51 0.51 0.44 3937
weighted avg 0.75 0.50 0.57 3937
Overall, predicting accuracy of approximately 62% and 50% for the two models and the low predictive accuracy of the minority class (unlikely to vaccinate) indicate that the performance of our models is far from optimal. However, the purpose of this lab is not to build a well-performing model but to introduce you to an end-to-end machine learning workflow.
Keep in mind that it is not a good research practice to now — after you tested the models on the test data — go back and fine-tune the training models as this will introduce overfitting. A good research practice is to fine-tune and improve your model(s) at the stage of training and cross-validation (not after you tested your model on unseen data). Once you select your best performing model(s) at the cross-validation stage, you test the model using the test data and report the performance scores.
As part of your data analysis exercises, you will have another opportunity to build a new machine learning model and evaluate model performance.